Build a Question/Answering system over SQL data
This guide assumes familiarity with the following concepts:
Enabling a LLM system to query structured data can be qualitatively different from unstructured text data. Whereas in the latter it is common to generate text that can be searched against a vector database, the approach for structured data is often for the LLM to write and execute queries in a DSL, such as SQL. In this guide we'll go over the basic ways to create a Q&A system over tabular data in databases. We will cover implementations using both chains and agents. These systems will allow us to ask a question about the data in a database and get back a natural language answer. The main difference between the two is that our agent can query the database in a loop as many times as it needs to answer the question.
⚠️ Security note ⚠️
Building Q&A systems of SQL databases requires executing model-generated SQL queries. There are inherent risks in doing this. Make sure that your database connection permissions are always scoped as narrowly as possible for your chain/agent's needs. This will mitigate though not eliminate the risks of building a model-driven system. For more on general security best practices, see here.
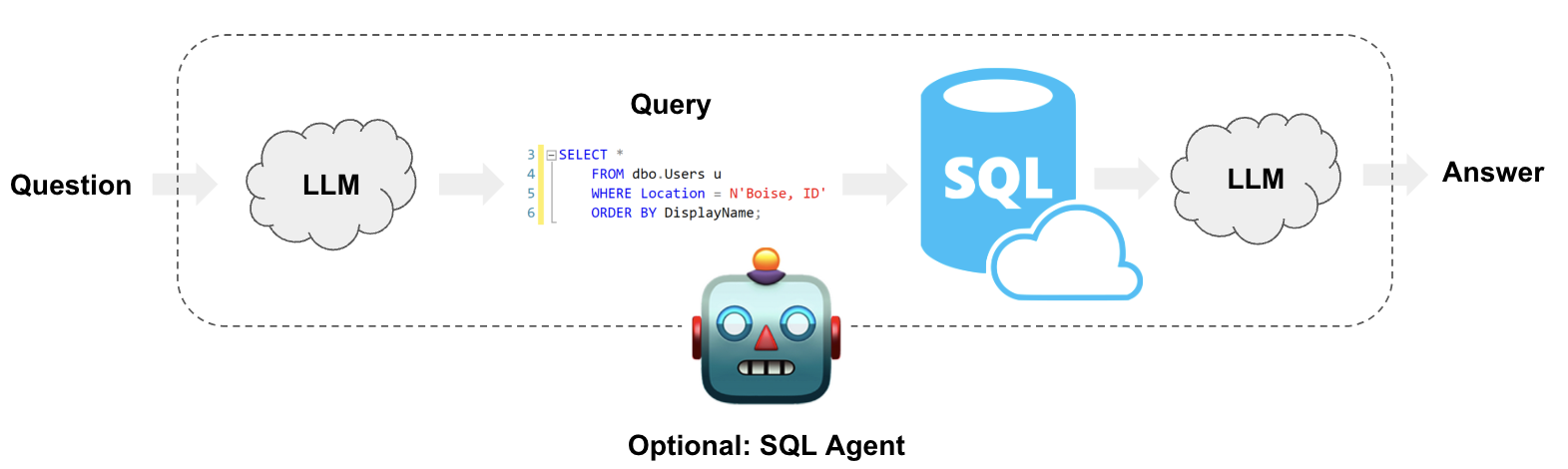
Architecture
At a high-level, the steps of these systems are:
- Convert question to SQL query: Model converts user input to a SQL query.
- Execute SQL query: Execute the query.
- Answer the question: Model responds to user input using the query results.
Note that querying data in CSVs can follow a similar approach. See our how-to guide on question-answering over CSV data for more detail.
Setup
First, get required packages and set environment variables:
%%capture --no-stderr
%pip install --upgrade --quiet langchain-community langchainhub langgraph
# Comment out the below to opt-out of using LangSmith in this notebook. Not required.
if not os.environ.get("LANGCHAIN_API_KEY"):
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
os.environ["LANGCHAIN_TRACING_V2"] = "true"
Sample data
The below example will use a SQLite connection with the Chinook database, which is a sample database that represents a digital media store. Follow these installation steps to create Chinook.db in the same directory as this notebook. You can also download and build the database via the command line:
curl -s https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql | sqlite3 Chinook.db
Now, Chinook.db is in our directory and we can interface with it using the SQLAlchemy-driven SQLDatabase class:
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
db.run("SELECT * FROM Artist LIMIT 10;")
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
"[(1, 'AC/DC'), (2, 'Accept'), (3, 'Aerosmith'), (4, 'Alanis Morissette'), (5, 'Alice In Chains'), (6, 'Antônio Carlos Jobim'), (7, 'Apocalyptica'), (8, 'Audioslave'), (9, 'BackBeat'), (10, 'Billy Cobham')]"
Great! We've got a SQL database that we can query. Now let's try hooking it up to an LLM.
Chains
Chains are compositions of predictable steps. In LangGraph, we can represent a chain via simple sequence of nodes. Let's create a sequence of steps that, given a question, does the following:
- converts the question into a SQL query;
- executes the query;
- uses the result to answer the original question.
There are scenarios not supported by this arrangement. For example, this system will execute a SQL query for any user input-- even "hello". Importantly, as we'll see below, some questions require more than one query to answer. We will address these scenarios in the Agents section.
Application state
The LangGraph state of our application controls what data is input to the application, transferred between steps, and output by the application. It is typically a TypedDict, but can also be a Pydantic BaseModel.
For this application, we can just keep track of the input question, generated query, query result, and generated answer:
from typing_extensions import TypedDict
class State(TypedDict):
question: str
query: str
result: str
answer: str
Now we just need functions that operate on this state and populate its contents.
Convert question to SQL query
The first step is to take the user input and convert it to a SQL query. To reliably obtain SQL queries (absent markdown formatting and explanations or clarifications), we will make use of LangChain's structured output abstraction.
Let's select a chat model for our application:
- OpenAI
- Anthropic
- Azure
- AWS
- Cohere
- NVIDIA
- FireworksAI
- Groq
- MistralAI
- TogetherAI
- Databricks
pip install -qU langchain-openai
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
pip install -qU langchain-anthropic
import getpass
import os
os.environ["ANTHROPIC_API_KEY"] = getpass.getpass()
from langchain_anthropic import ChatAnthropic
llm = ChatAnthropic(model="claude-3-5-sonnet-20240620")
pip install -qU langchain-openai
import getpass
import os
os.environ["AZURE_OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import AzureChatOpenAI
llm = AzureChatOpenAI(
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],
openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)
pip install -qU langchain-google-vertexai
# Ensure your VertexAI credentials are configured
from langchain_google_vertexai import ChatVertexAI
llm = ChatVertexAI(model="gemini-1.5-flash")
pip install -qU langchain-aws
# Ensure your AWS credentials are configured
from langchain_aws import ChatBedrock
llm = ChatBedrock(model="anthropic.claude-3-5-sonnet-20240620-v1:0",
beta_use_converse_api=True)
pip install -qU langchain-cohere
import getpass
import os
os.environ["COHERE_API_KEY"] = getpass.getpass()
from langchain_cohere import ChatCohere
llm = ChatCohere(model="command-r-plus")
pip install -qU langchain-nvidia-ai-endpoints
import getpass
import os
os.environ["NVIDIA_API_KEY"] = getpass.getpass()
from langchain_nvidia_ai_endpoints import ChatNVIDIA
llm = ChatNVIDIA(model="meta/llama3-70b-instruct")
pip install -qU langchain-fireworks
import getpass
import os
os.environ["FIREWORKS_API_KEY"] = getpass.getpass()
from langchain_fireworks import ChatFireworks
llm = ChatFireworks(model="accounts/fireworks/models/llama-v3p1-70b-instruct")
pip install -qU langchain-groq
import getpass
import os
os.environ["GROQ_API_KEY"] = getpass.getpass()
from langchain_groq import ChatGroq
llm = ChatGroq(model="llama3-8b-8192")
pip install -qU langchain-mistralai
import getpass
import os
os.environ["MISTRAL_API_KEY"] = getpass.getpass()
from langchain_mistralai import ChatMistralAI
llm = ChatMistralAI(model="mistral-large-latest")
pip install -qU langchain-openai
import getpass
import os
os.environ["TOGETHER_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
base_url="https://api.together.xyz/v1",
api_key=os.environ["TOGETHER_API_KEY"],
model="mistralai/Mixtral-8x7B-Instruct-v0.1",
)
pip install -qU databricks-langchain
import getpass
import os
os.environ["DATABRICKS_TOKEN"] = getpass.getpass()
from databricks_langchain import ChatDatabricks
os.environ["DATABRICKS_HOST"] = "https://example.staging.cloud.databricks.com/serving-endpoints"
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-1-70b-instruct")
We will pull a prompt from the Prompt Hub to instruct the model.
from langchain import hub
query_prompt_template = hub.pull("langchain-ai/sql-query-system-prompt")
assert len(query_prompt_template.messages) == 1
query_prompt_template.messages[0].pretty_print()
================================[1m System Message [0m================================
Given an input question, create a syntactically correct [33;1m[1;3m{dialect}[0m query to run to help find the answer. Unless the user specifies in his question a specific number of examples they wish to obtain, always limit your query to at most [33;1m[1;3m{top_k}[0m results. You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for a the few relevant columns given the question.
Pay attention to use only the column names that you can see in the schema description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Only use the following tables:
[33;1m[1;3m{table_info}[0m
Question: [33;1m[1;3m{input}[0m
The prompt includes several parameters we will need to populate, such as the SQL dialect and table schemas. LangChain's SQLDatabase object includes methods to help with this. Our write_query step will just populate these parameters and prompt a model to generate the SQL query:
from typing_extensions import Annotated
class QueryOutput(TypedDict):
"""Generated SQL query."""
query: Annotated[str, ..., "Syntactically valid SQL query."]
def write_query(state: State):
"""Generate SQL query to fetch information."""
prompt = query_prompt_template.invoke(
{
"dialect": db.dialect,
"top_k": 10,
"table_info": db.get_table_info(),
"input": state["question"],
}
)
structured_llm = llm.with_structured_output(QueryOutput)
result = structured_llm.invoke(prompt)
return {"query": result["query"]}
Let's test it out:
write_query({"question": "How many Employees are there?"})
{'query': 'SELECT COUNT(EmployeeId) AS EmployeeCount FROM Employee;'}
Execute query
This is the most dangerous part of creating a SQL chain. Consider carefully if it is OK to run automated queries over your data. Minimize the database connection permissions as much as possible. Consider adding a human approval step to you chains before query execution (see below).
To execute the query, we will load a tool from langchain-community. Our execute_query node will just wrap this tool:
from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool
def execute_query(state: State):
"""Execute SQL query."""
execute_query_tool = QuerySQLDataBaseTool(db=db)
return {"result": execute_query_tool.invoke(state["query"])}
Testing this step:
execute_query({"query": "SELECT COUNT(EmployeeId) AS EmployeeCount FROM Employee;"})
{'result': '[(8,)]'}
Generate answer
Finally, our last step generates an answer to the question given the information pulled from the database:
def generate_answer(state: State):
"""Answer question using retrieved information as context."""
prompt = (
"Given the following user question, corresponding SQL query, "
"and SQL result, answer the user question.\n\n"
f'Question: {state["question"]}\n'
f'SQL Query: {state["query"]}\n'
f'SQL Result: {state["result"]}'
)
response = llm.invoke(prompt)
return {"answer": response.content}
Orchestrating with LangGraph
Finally, we compile our application into a single graph object. In this case, we are just connecting the three steps into a single sequence.
from langgraph.graph import START, StateGraph
graph_builder = StateGraph(State).add_sequence(
[write_query, execute_query, generate_answer]
)
graph_builder.add_edge(START, "write_query")
graph = graph_builder.compile()
LangGraph also comes with built-in utilities for visualizing the control flow of your application:
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))

Let's test our application! Note that we can stream the results of individual steps:
for step in graph.stream(
{"question": "How many employees are there?"}, stream_mode="updates"
):
print(step)
{'write_query': {'query': 'SELECT COUNT(EmployeeId) AS EmployeeCount FROM Employee;'}}
{'execute_query': {'result': '[(8,)]'}}
{'generate_answer': {'answer': 'There are 8 employees.'}}
Check out the LangSmith trace.
Human-in-the-loop
LangGraph supports a number of features that can be useful for this workflow. One of them is human-in-the-loop: we can interrupt our application before sensitive steps (such as the execution of a SQL query) for human review. This is enabled by LangGraph's persistence layer, which saves run progress to your storage of choice. Below, we specify storage in-memory:
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory, interrupt_before=["execute_query"])
# Now that we're using persistence, we need to specify a thread ID
# so that we can continue the run after review.
config = {"configurable": {"thread_id": "1"}}
display(Image(graph.get_graph().draw_mermaid_png()))

Let's repeat the same run, adding in a simple yes/no approval step:
for step in graph.stream(
{"question": "How many employees are there?"},
config,
stream_mode="updates",
):
print(step)
try:
user_approval = input("Do you want to go to execute query? (yes/no): ")
except Exception:
user_approval = "no"
if user_approval.lower() == "yes":
# If approved, continue the graph execution
for step in graph.stream(None, config, stream_mode="updates"):
print(step)
else:
print("Operation cancelled by user.")
{'write_query': {'query': 'SELECT COUNT(EmployeeId) AS NumberOfEmployees FROM Employee;'}}
{'__interrupt__': ()}
``````output
Do you want to go to execute query? (yes/no): yes
``````output
{'execute_query': {'result': '[(8,)]'}}
{'generate_answer': {'answer': 'There are 8 employees.'}}
See this LangGraph guide for more detail and examples.
Next steps
For more complex query-generation, we may want to create few-shot prompts or add query-checking steps. For advanced techniques like this and more check out:
- Prompting strategies: Advanced prompt engineering techniques.
- Query checking: Add query validation and error handling.
- Large databases: Techniques for working with large databases.
Agents
Agents leverage the reasoning capabilities of LLMs to make decisions during execution. Using agents allows you to offload additional discretion over the query generation and execution process. Although their behavior is less predictable than the above "chain", they feature some advantages:
- They can query the database as many times as needed to answer the user question.
- They can recover from errors by running a generated query, catching the traceback and regenerating it correctly.
- They can answer questions based on the databases' schema as well as on the databases' content (like describing a specific table).
Below we assemble a minimal SQL agent. We will equip it with a set of tools using LangChain's SQLDatabaseToolkit. Using LangGraph's pre-built ReAct agent constructor, we can do this in one line.
Check out LangGraph's SQL Agent Tutorial for a more advanced formulation of a SQL agent.
The SQLDatabaseToolkit includes tools that can:
- Create and execute queries
- Check query syntax
- Retrieve table descriptions
- ... and more
from langchain_community.agent_toolkits import SQLDatabaseToolkit
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
tools = toolkit.get_tools()
tools
[QuerySQLDataBaseTool(description="Input to this tool is a detailed and correct SQL query, output is a result from the database. If the query is not correct, an error message will be returned. If an error is returned, rewrite the query, check the query, and try again. If you encounter an issue with Unknown column 'xxxx' in 'field list', use sql_db_schema to query the correct table fields.", db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x114414d00>),
InfoSQLDatabaseTool(description='Input to this tool is a comma-separated list of tables, output is the schema and sample rows for those tables. Be sure that the tables actually exist by calling sql_db_list_tables first! Example Input: table1, table2, table3', db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x114414d00>),
ListSQLDatabaseTool(db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x114414d00>),
QuerySQLCheckerTool(description='Use this tool to double check if your query is correct before executing it. Always use this tool before executing a query with sql_db_query!', db=<langchain_community.utilities.sql_database.SQLDatabase object at 0x114414d00>, llm=ChatOpenAI(client=<openai.resources.chat.completions.Completions object at 0x120110d00>, async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x120112e00>, root_client=<openai.OpenAI object at 0x107a58370>, root_async_client=<openai.AsyncOpenAI object at 0x120110d60>, model_name='gpt-4o', temperature=0.0, model_kwargs={}, openai_api_key=SecretStr('**********')), llm_chain=LLMChain(verbose=False, prompt=PromptTemplate(input_variables=['dialect', 'query'], input_types={}, partial_variables={}, template='\n{query}\nDouble check the {dialect} query above for common mistakes, including:\n- Using NOT IN with NULL values\n- Using UNION when UNION ALL should have been used\n- Using BETWEEN for exclusive ranges\n- Data type mismatch in predicates\n- Properly quoting identifiers\n- Using the correct number of arguments for functions\n- Casting to the correct data type\n- Using the proper columns for joins\n\nIf there are any of the above mistakes, rewrite the query. If there are no mistakes, just reproduce the original query.\n\nOutput the final SQL query only.\n\nSQL Query: '), llm=ChatOpenAI(client=<openai.resources.chat.completions.Completions object at 0x120110d00>, async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x120112e00>, root_client=<openai.OpenAI object at 0x107a58370>, root_async_client=<openai.AsyncOpenAI object at 0x120110d60>, model_name='gpt-4o', temperature=0.0, model_kwargs={}, openai_api_key=SecretStr('**********')), output_parser=StrOutputParser(), llm_kwargs={}))]
System Prompt
We will also want to load a system prompt for our agent. This will consist of instructions for how to behave.
from langchain import hub
prompt_template = hub.pull("langchain-ai/sql-agent-system-prompt")
assert len(prompt_template.messages) == 1
prompt_template.messages[0].pretty_print()
================================[1m System Message [0m================================
You are an agent designed to interact with a SQL database.
Given an input question, create a syntactically correct [33;1m[1;3m{dialect}[0m query to run, then look at the results of the query and return the answer.
Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most [33;1m[1;3m{top_k}[0m results.
You can order the results by a relevant column to return the most interesting examples in the database.
Never query for all the columns from a specific table, only ask for the relevant columns given the question.
You have access to tools for interacting with the database.
Only use the below tools. Only use the information returned by the below tools to construct your final answer.
You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again.
DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database.
To start you should ALWAYS look at the tables in the database to see what you can query.
Do NOT skip this step.
Then you should query the schema of the most relevant tables.
Let's populate the parameters highlighted in the prompt:
system_message = prompt_template.format(dialect="SQLite", top_k=5)
Initializing agent
We will use a prebuilt LangGraph agent to build our agent
from langchain_core.messages import HumanMessage
from langgraph.prebuilt import create_react_agent
agent_executor = create_react_agent(llm, tools, state_modifier=system_message)
Consider how the agent responds to the below question:
question = "Which country's customers spent the most?"
for step in agent_executor.stream(
{"messages": [{"role": "user", "content": question}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()
================================[1m Human Message [0m=================================
Which country's customers spent the most?
==================================[1m Ai Message [0m==================================
Tool Calls:
sql_db_list_tables (call_J7Cj6d9gqkaOwiB99fv8y6uh)
Call ID: call_J7Cj6d9gqkaOwiB99fv8y6uh
Args:
=================================[1m Tool Message [0m=================================
Name: sql_db_list_tables
Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
==================================[1m Ai Message [0m==================================
Tool Calls:
sql_db_schema (call_zF4O1BfsAfEfQP85vvHPu6Kp)
Call ID: call_zF4O1BfsAfEfQP85vvHPu6Kp
Args:
table_names: Customer, Invoice
=================================[1m Tool Message [0m=================================
Name: sql_db_schema
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2021-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2021-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2021-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
==================================[1m Ai Message [0m==================================
Tool Calls:
sql_db_query_checker (call_YkdCcgJOzVUc4IsI3ytLPf0x)
Call ID: call_YkdCcgJOzVUc4IsI3ytLPf0x
Args:
query: SELECT c.Country, SUM(i.Total) as TotalSpent FROM Customer c JOIN Invoice i ON c.CustomerId = i.CustomerId GROUP BY c.Country ORDER BY TotalSpent DESC LIMIT 1;
=================================[1m Tool Message [0m=================================
Name: sql_db_query_checker
\`\`\`sql
SELECT c.Country, SUM(i.Total) as TotalSpent FROM Customer c JOIN Invoice i ON c.CustomerId = i.CustomerId GROUP BY c.Country ORDER BY TotalSpent DESC LIMIT 1;
\`\`\`
==================================[1m Ai Message [0m==================================
Tool Calls:
sql_db_query (call_cojsHW4TTadu9fe6oooMr4Y9)
Call ID: call_cojsHW4TTadu9fe6oooMr4Y9
Args:
query: SELECT c.Country, SUM(i.Total) as TotalSpent FROM Customer c JOIN Invoice i ON c.CustomerId = i.CustomerId GROUP BY c.Country ORDER BY TotalSpent DESC LIMIT 1;
=================================[1m Tool Message [0m=================================
Name: sql_db_query
[('USA', 523.06)]
==================================[1m Ai Message [0m==================================
The country whose customers spent the most is the USA, with a total spending of 523.06.
You can also use the LangSmith trace to visualize these steps and associated metadata.
Note that the agent executes multiple queries until it has the information it needs:
- List available tables;
- Retrieves the schema for three tables;
- Queries multiple of the tables via a join operation.
The agent is then able to use the result of the final query to generate an answer to the original question.
The agent can similarly handle qualitative questions:
question = "Describe the playlisttrack table"
for step in agent_executor.stream(
{"messages": [{"role": "user", "content": question}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()
================================[1m Human Message [0m=================================
Describe the playlisttrack table
==================================[1m Ai Message [0m==================================
Tool Calls:
sql_db_list_tables (call_7o2lQBlRAoqGtbF17AW3b4RV)
Call ID: call_7o2lQBlRAoqGtbF17AW3b4RV
Args:
=================================[1m Tool Message [0m=================================
Name: sql_db_list_tables
Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
==================================[1m Ai Message [0m==================================
Tool Calls:
sql_db_schema (call_xZx5tqzBAlPNiktWsuoafd4t)
Call ID: call_xZx5tqzBAlPNiktWsuoafd4t
Args:
table_names: PlaylistTrack
=================================[1m Tool Message [0m=================================
Name: sql_db_schema
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
/*
3 rows from PlaylistTrack table:
PlaylistId TrackId
1 3402
1 3389
1 3390
*/
==================================[1m Ai Message [0m==================================
The `PlaylistTrack` table is a junction table that connects playlists and tracks. It has the following columns:
- `PlaylistId`: An integer that references the `PlaylistId` in the `Playlist` table. It is part of the composite primary key.
- `TrackId`: An integer that references the `TrackId` in the `Track` table. It is also part of the composite primary key.
The primary key for this table is a combination of `PlaylistId` and `TrackId`, ensuring that each track can only appear once in a specific playlist. The table also enforces foreign key constraints to maintain referential integrity with the `Playlist` and `Track` tables.
Dealing with high-cardinality columns
In order to filter columns that contain proper nouns such as addresses, song names or artists, we first need to double-check the spelling in order to filter the data correctly.
We can achieve this by creating a vector store with all the distinct proper nouns that exist in the database. We can then have the agent query that vector store each time the user includes a proper noun in their question, to find the correct spelling for that word. In this way, the agent can make sure it understands which entity the user is referring to before building the target query.
First we need the unique values for each entity we want, for which we define a function that parses the result into a list of elements:
import ast
import re
def query_as_list(db, query):
res = db.run(query)
res = [el for sub in ast.literal_eval(res) for el in sub if el]
res = [re.sub(r"\b\d+\b", "", string).strip() for string in res]
return list(set(res))
artists = query_as_list(db, "SELECT Name FROM Artist")
albums = query_as_list(db, "SELECT Title FROM Album")
albums[:5]
['In Through The Out Door',
'Transmission',
'Battlestar Galactica (Classic), Season',
'A Copland Celebration, Vol. I',
'Quiet Songs']
Using this function, we can create a retriever tool that the agent can execute at its discretion.
Let's select an embeddings model and vector store for this step:
Select an embedding model:
- OpenAI
- Azure
- AWS
- HuggingFace
- Ollama
- Cohere
- MistralAI
- Nomic
- NVIDIA
- Fake
pip install -qU langchain-openai
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
pip install -qU langchain-openai
import getpass
os.environ["AZURE_OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import AzureOpenAIEmbeddings
embeddings = AzureOpenAIEmbeddings(
azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],
azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],
openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)
pip install -qU langchain-google-vertexai
from langchain_google_vertexai import VertexAIEmbeddings
embeddings = VertexAIEmbeddings(model="text-embedding-004")
pip install -qU langchain-aws
from langchain_aws import BedrockEmbeddings
embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0")
pip install -qU langchain-huggingface
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
pip install -qU langchain-ollama
from langchain_ollama import OllamaEmbeddings
embeddings = OllamaEmbeddings(model="llama3")
pip install -qU langchain-cohere
import getpass
os.environ["COHERE_API_KEY"] = getpass.getpass()
from langchain_cohere import CohereEmbeddings
embeddings = CohereEmbeddings(model="embed-english-v3.0")
pip install -qU langchain-mistralai
import getpass
os.environ["MISTRALAI_API_KEY"] = getpass.getpass()
from langchain_mistralai import MistralAIEmbeddings
embeddings = MistralAIEmbeddings(model="mistral-embed")
pip install -qU langchain-nomic
import getpass
os.environ["NOMIC_API_KEY"] = getpass.getpass()
from langchain_nomic import NomicEmbeddings
embeddings = NomicEmbeddings(model="nomic-embed-text-v1.5")
pip install -qU langchain-nvidia-ai-endpoints
import getpass
os.environ["NVIDIA_API_KEY"] = getpass.getpass()
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
embeddings = NVIDIAEmbeddings(model="NV-Embed-QA")
pip install -qU langchain-core
from langchain_core.embeddings import DeterministicFakeEmbedding
embeddings = DeterministicFakeEmbedding(size=4096)
Select a vector store:
- In-memory
- AstraDB
- Chroma
- FAISS
- Milvus
- MongoDB
- PGVector
- Pinecone
- Qdrant
pip install -qU langchain-core
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
pip install -qU langchain-astradb
from langchain_astradb import AstraDBVectorStore
vector_store = AstraDBVectorStore(
embedding=embeddings,
api_endpoint=ASTRA_DB_API_ENDPOINT,
collection_name="astra_vector_langchain",
token=ASTRA_DB_APPLICATION_TOKEN,
namespace=ASTRA_DB_NAMESPACE,
)
pip install -qU langchain-chroma
from langchain_chroma import Chroma
vector_store = Chroma(embedding_function=embeddings)
pip install -qU langchain-community
from langchain_community.vectorstores import FAISS
vector_store = FAISS(embedding_function=embeddings)
pip install -qU langchain-milvus
from langchain_milvus import Milvus
vector_store = Milvus(embedding_function=embeddings)
pip install -qU langchain-mongodb
from langchain_mongodb import MongoDBAtlasVectorSearch
vector_store = MongoDBAtlasVectorSearch(
embedding=embeddings,
collection=MONGODB_COLLECTION,
index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME,
relevance_score_fn="cosine",
)
pip install -qU langchain-postgres
from langchain_postgres import PGVector
vector_store = PGVector(
embedding=embeddings,
collection_name="my_docs",
connection="postgresql+psycopg://...",
)
pip install -qU langchain-pinecone
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone
pc = Pinecone(api_key=...)
index = pc.Index(index_name)
vector_store = PineconeVectorStore(embedding=embeddings, index=index)
pip install -qU langchain-qdrant
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
client = QdrantClient(":memory:")
vector_store = QdrantVectorStore(
client=client,
collection_name="test",
embedding=embeddings,
)
We can now construct a retrieval tool that can search over relevant proper nouns in the database:
from langchain.agents.agent_toolkits import create_retriever_tool
_ = vector_store.add_texts(artists + albums)
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
description = (
"Use to look up values to filter on. Input is an approximate spelling "
"of the proper noun, output is valid proper nouns. Use the noun most "
"similar to the search."
)
retriever_tool = create_retriever_tool(
retriever,
name="search_proper_nouns",
description=description,
)
Let's try it out:
print(retriever_tool.invoke("Alice Chains"))
Alice In Chains
Alanis Morissette
Pearl Jam
Pearl Jam
Audioslave
This way, if the agent determines it needs to write a filter based on an artist along the lines of "Alice Chains", it can first use the retriever tool to observe relevant values of a column.
Putting this together:
# Add to system message
suffix = (
"If you need to filter on a proper noun like a Name, you must ALWAYS first look up "
"the filter value using the 'search_proper_nouns' tool! Do not try to "
"guess at the proper name - use this function to find similar ones."
)
system = f"{system_message}\n\n{suffix}"
tools.append(retriever_tool)
agent = create_react_agent(llm, tools, state_modifier=system)
question = "How many albums does alis in chain have?"
for step in agent.stream(
{"messages": [{"role": "user", "content": question}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()
================================[1m Human Message [0m=================================
How many albums does alis in chain have?
==================================[1m Ai Message [0m==================================
Tool Calls:
search_proper_nouns (call_8ryjsRPLAr79mM3Qvnq6gTOH)
Call ID: call_8ryjsRPLAr79mM3Qvnq6gTOH
Args:
query: alis in chain
=================================[1m Tool Message [0m=================================
Name: search_proper_nouns
Alice In Chains
Aisha Duo
Xis
Da Lama Ao Caos
A-Sides
==================================[1m Ai Message [0m==================================
Tool Calls:
sql_db_list_tables (call_NJjtCpU89MBMplssjn1z0xzq)
Call ID: call_NJjtCpU89MBMplssjn1z0xzq
Args:
search_proper_nouns (call_1BfrueC9koSIyi4OfMu2Ao8q)
Call ID: call_1BfrueC9koSIyi4OfMu2Ao8q
Args:
query: Alice In Chains
=================================[1m Tool Message [0m=================================
Name: search_proper_nouns
Alice In Chains
Pearl Jam
Pearl Jam
Foo Fighters
Soundgarden
==================================[1m Ai Message [0m==================================
Tool Calls:
sql_db_schema (call_Kn09w9jd9swcNzIZ1b5MlKID)
Call ID: call_Kn09w9jd9swcNzIZ1b5MlKID
Args:
table_names: Album, Artist
=================================[1m Tool Message [0m=================================
Name: sql_db_schema
CREATE TABLE "Album" (
"AlbumId" INTEGER NOT NULL,
"Title" NVARCHAR(160) NOT NULL,
"ArtistId" INTEGER NOT NULL,
PRIMARY KEY ("AlbumId"),
FOREIGN KEY("ArtistId") REFERENCES "Artist" ("ArtistId")
)
/*
3 rows from Album table:
AlbumId Title ArtistId
1 For Those About To Rock We Salute You 1
2 Balls to the Wall 2
3 Restless and Wild 2
*/
CREATE TABLE "Artist" (
"ArtistId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("ArtistId")
)
/*
3 rows from Artist table:
ArtistId Name
1 AC/DC
2 Accept
3 Aerosmith
*/
==================================[1m Ai Message [0m==================================
Tool Calls:
sql_db_query (call_WkHRiPcBoGN9bc58MIupRHKP)
Call ID: call_WkHRiPcBoGN9bc58MIupRHKP
Args:
query: SELECT COUNT(*) FROM Album WHERE ArtistId = (SELECT ArtistId FROM Artist WHERE Name = 'Alice In Chains')
=================================[1m Tool Message [0m=================================
Name: sql_db_query
[(1,)]
==================================[1m Ai Message [0m==================================
Alice In Chains has released 1 album in the database.
As we can see, both in the streamed steps and in the LangSmith trace, the agent used the search_proper_nouns tool in order to check how to correctly query the database for this specific artist.